Verzonden op 20-02-2026 07:35

ByteDance lanceert Seedance 2.0: AI-video doorbreekt uncanny valleyDe nieuwe AI-videomodel Seedance 2.0 van TikTok-maker ByteDance gaat viraal op sociale media met hyper-realistische video's. Waar eerdere modellen worstelden met zwevende objecten en onnatuurlijke bewegingen, produceert Seedance 2.0 beelden die nauwelijks van echt te onderscheiden zijn – van Lord of the Rings-reimaginaties tot martial arts-gevechten. Dit is relevant omdat video-generatie lang achterbleef bij tekst en afbeeldingen. Als Seedance 2.0 inderdaad zo consistent is als de voorbeelden suggereren, verschuift de bottleneck van 'technisch mogelijk' naar 'creatief concept en regie'. Voor marketeers, trainingsafdelingen en contentteams betekent dat: productietijd en -kosten kunnen dramatisch dalen. Let wel: de meeste voorbeelden duren enkele seconden en zijn zorgvuldig geselecteerd. Langere clips met complexe camera-bewegingen zijn nog steeds lastig. En de juridische en ethische vragen rond deepfakes blijven onbeantwoord. |
Google Gemini 3 Deep Think haalt 84,6% op ARC-AGI-2, voorbij ClaudeOp 13 februari 2026 heeft Google een grote upgrade uitgebracht van Gemini 3 Deep Think, een gespecialiseerde reasoning-modus voor wetenschap en engineering. Het systeem scoort nu 84,6% op ARC-AGI-2, de moeilijkste publieke reasoning-test, geverifieerd door de ARC Prize Foundation. Dat is 1.103 punten beter dan Claude Opus 4.6. Waar traditionele reasoning-modellen vaak vastlopen in één denkpad, verkent Deep Think meerdere scenario's parallel. Dat maakt het systeem geschikter voor complexe problemen waarbij je verschillende oplossingsrichtingen wilt vergelijken – denk aan optimalisatie van supply chains of simulatie van beleidsscenario's. Voor organisaties die zwaar rekenwerk uitbesteden aan AI betekent dit een nieuwe benchmark: wat voorheen alleen met menselijke experts kon, komt nu binnen bereik van een model. De vraag is natuurlijk: hoe duur is zo'n reasoning-sessie vergeleken met GPT-5.2 of Claude? Test Deep Think op een intern probleemtype waar je nu externe adviseurs voor inzet – bijvoorbeeld scenarioanalyse of risicosimulatie – en vergelijk de kwaliteit met eerdere modellen. |
OpenAI lanceert GPT-5.3-Codex-Spark: sneller coding-model op nieuwe chipOpenAI heeft op 13 februari 2026 GPT-5.3-Codex-Spark geïntroduceerd, een kleinere en snellere versie van zijn agentic coding-tool. Het model draait op een nieuwe chip en is ontworpen voor real-time code-assistentie met lagere latency dan eerdere versies. De timing is interessant: vorige week kondigde OpenAI GPT-5.3 Codex aan als computer-use agent, en nu volgt een geoptimaliseerde variant die vooral snelheid prioriteert. Voor teams die code-assistenten inzetten in IDE's of CI/CD-pipelines kan die latency het verschil maken tussen 'bruikbaar' en 'storend'. De architectuur is kleiner, wat betekent dat je mogelijk lagere compute-kosten hebt per request. Dat maakt het interessanter voor hoge volumes – bijvoorbeeld als je duizenden developers tegelijk wilt bedienen. Wel blijft de vraag hoe de kwaliteit zich verhoudt tot het grotere model bij complexe refactorings.
|
Ex-GitHub CEO lanceert open-source CLI om agent-sessies te trackenDe voormalige CEO van GitHub heeft een open-source command-line tool uitgebracht waarmee je AI-agent-sessies kunt vastleggen en versie-beheren. Het tool lost een praktisch probleem op: als je agents autonome taken laat uitvoeren, wil je achteraf kunnen reconstrueren welke stappen ze hebben gezet en waarom. Dat is vooral waardevol voor compliance en debugging. In regulated omgevingen – financieel, medisch, overheid – moet je kunnen aantonen hoe een beslissing tot stand kwam. Tot nu toe was dat lastig omdat agents vaak in black-box-modus werken. Deze CLI maakt die reasoning-chains transparant en reproduceerbaar. Voor teams die agents in productie draaien, is dit een no-brainer om te testen. De tool is open source, dus je kunt zelf aanpassingen maken voor jouw stack. Verwacht alleen niet dat het meteen alle observability-problemen oplost – je moet nog steeds zelf bepalen wat je logt en hoe je dat analyseert.
|
Google lanceert officieel Skills-pakket voor Gemini API-ontwikkelaarsGoogle heeft op 13 februari 2026 een officieel Skills-pakket uitgebracht voor ontwikkelaars die werken met de Gemini API. Het pakket bundelt veelgebruikte functionaliteiten en integratiepatronen, waardoor je sneller Gemini-applicaties kunt bouwen zonder telkens dezelfde boilerplate-code te schrijven. Dit soort developer-experience-verbeteringen zijn cruciaal in de strijd om marktaandeel. OpenAI heeft een voorsprong in ecosysteem en tooling, en Google probeert die in te halen. Voor bedrijven die multi-model-strategieën overwegen, maakt dit Gemini aantrekkelijker – niet omdat het model beter is, maar omdat de onboarding sneller gaat. De praktische impact hangt af van hoe goed het pakket aansluit bij jouw use case. Als je al custom wrappers hebt gebouwd, is de meerwaarde beperkt. Maar voor nieuwe projecten scheelt het waarschijnlijk dagen aan setup-tijd.
|
Anthropic meldt 4% van GitHub-commits via Claude Code, haalt $30 miljard opAnthropic rapporteert dat 4% van alle commits op GitHub nu gegenereerd worden door Claude Code, en heeft tegelijkertijd $30 miljard opgehaald aan nieuwe financiering. Dat percentage klinkt klein, maar op schaal van GitHub – met miljoenen developers – is het een aanzienlijk volume. Het cijfer laat zien dat code-assistenten niet langer experimenteel zijn, maar stevig verankerd in dagelijkse workflows. Voor CTO's en engineering managers is de vraag niet meer óf je AI-coding introduceert, maar hoe je het veilig en efficiënt integreert. De $30 miljard fundingronde geeft Anthropic de middelen om Claude verder te professionaliseren – verwacht enterprise-features, compliance-tooling en langetermijn-support. Een kanttekening: 4% commits zegt niets over de kwaliteit of complexiteit van die code. Zijn het vooral boilerplate en tests, of ook architecturele beslissingen? Die nuance blijft belangrijk bij het bepalen van je eigen AI-coding-strategie. 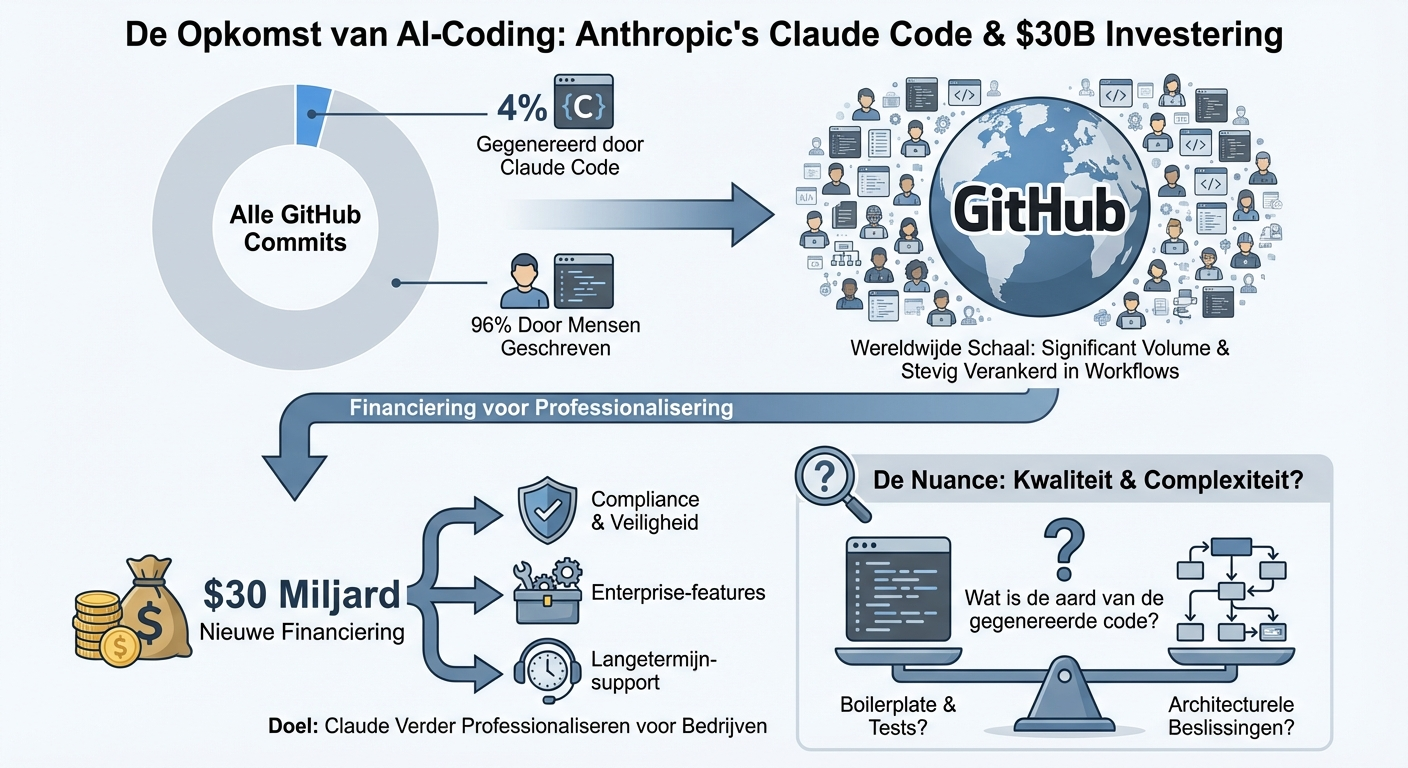
|
MiniMax onthult M2.5: open-source model met 80,2% op SWE-BenchMiniMax heeft M2.5 gelanceerd, een open-source model dat 80,2% scoort op SWE-Bench, een gestandaardiseerde test voor software engineering-taken. Dat is competitief met closed-source modellen en een signaal dat de kloof tussen open en proprietary verder kleiner wordt. Voor organisaties die eigen modellen willen fine-tunen of on-premise draaien, is dit goed nieuws. Je kunt M2.5 gebruiken als startpunt en aanpassen aan jouw codebase, zonder vendor lock-in of dataprivecy-zorgen. Dat maakt het vooral interessant voor sectoren met strikte compliance-eisen. Vergeet niet dat SWE-Bench een specifieke benchmark is – het test vooral bug-fixing en code-modificaties, niet architectuur of design. En open source betekent niet gratis: je hebt nog steeds compute-capaciteit en expertise nodig om het model te draaien en te onderhouden.
|