Verzonden op 28-05-2026 07:03

Taalmodellen leren 'slapen' om langere context te verwerkenOnderzoekers hebben een methode ontwikkeld waarmee taalmodellen lange context kunnen comprimeren via een mechanisme dat lijkt op hoe de hersenen tijdens de slaap herinneringen vastleggen. Het probleem dat dit oplost is concreet: naarmate de context langer wordt, worden modellen trager en duurder. Deze techniek kan dat afvlakken zonder dat je het contextvenster hoeft in te korten. Praktisch gezien gaat het nog om onderzoek en niet om een productfunctie, maar het geeft richting aan waar de volgende efficiëntiewinst in enterprise-AI zit. Houd het in de gaten als je werkt met toepassingen waarbij lange documenten of gespreksgeschiedenissen de bottleneck vormen.
|
OpenRouter haalt 113 miljoen dollar op terwijl model-routing explodeertOpenRouter heeft een financieringsronde van 113 miljoen dollar afgesloten, een teken dat de markt voor model-routing snel volwassen wordt. Model-routing houdt in dat je applicatie automatisch het goedkoopste of snelste model kiest voor een specifieke taak, zonder dat je daarvoor zelf logica hoeft te schrijven. Voor organisaties die meerdere AI-modellen gebruiken is dit direct relevant: je betaalt niet meer standaard voor GPT-4-niveau als een kleinere of goedkopere variant de klus ook klaart. De kanttekening is dat vendor lock-in verschuift van één modelaanbieder naar één routing-laag. Bekijk deze week of jouw huidige AI-integraties al gebruikmaken van routing-logica, of dat je voor elke taak nog steeds hetzelfde (dure) model aanroept. |
Micron en SK Hynix passeren elk de biljoen-grens in marktwaardeMicron en SK Hynix hebben voor het eerst een marktkapitalisatie van meer dan 1 biljoen dollar bereikt, gedreven door de aanhoudende vraag naar AI-geheugenchips. Tegelijk werd de Roundhill Memory ETF (DRAM) het snelst groeiende ETF ooit, met 10 miljard dollar aan beheerd vermogen. Dit laat zien dat de investeringsgolf in AI-hardware ook neerslaat bij de geheugenlaag die modellen nodig hebben om te draaien, en dus verder reikt dan alleen GPU-fabrikanten. Voor organisaties die AI-infrastructuur inkopen of plannen worden geheugenprijzen en -beschikbaarheid een even bepalende factor als rekenkracht. |
Figure-robots sorteren 88.000 pakketten bij JCPenneyFigure AI heeft robots ingezet in het magazijn van JCPenney en Brooks Brothers, waar ze 88.000 pakketten hebben gesorteerd. Ter vergelijking: in een eerdere test sorteerde een menselijke stagiair in acht uur 12.924 pakketten, de robot deed er 12.732. De nieuwe cijfers van 88.000 pakketten wijzen op een opschaling naar productieomgevingen, geen pilot meer. Voor logistiek en retail verschuift de discussie over robotisering van magazijnwerk daarmee van 'of' naar 'wanneer'. De vraag is niet of robots mensen hier vervangen, maar op welke tijdshorizon en tegen welke operationele kosten dat rendabel wordt. 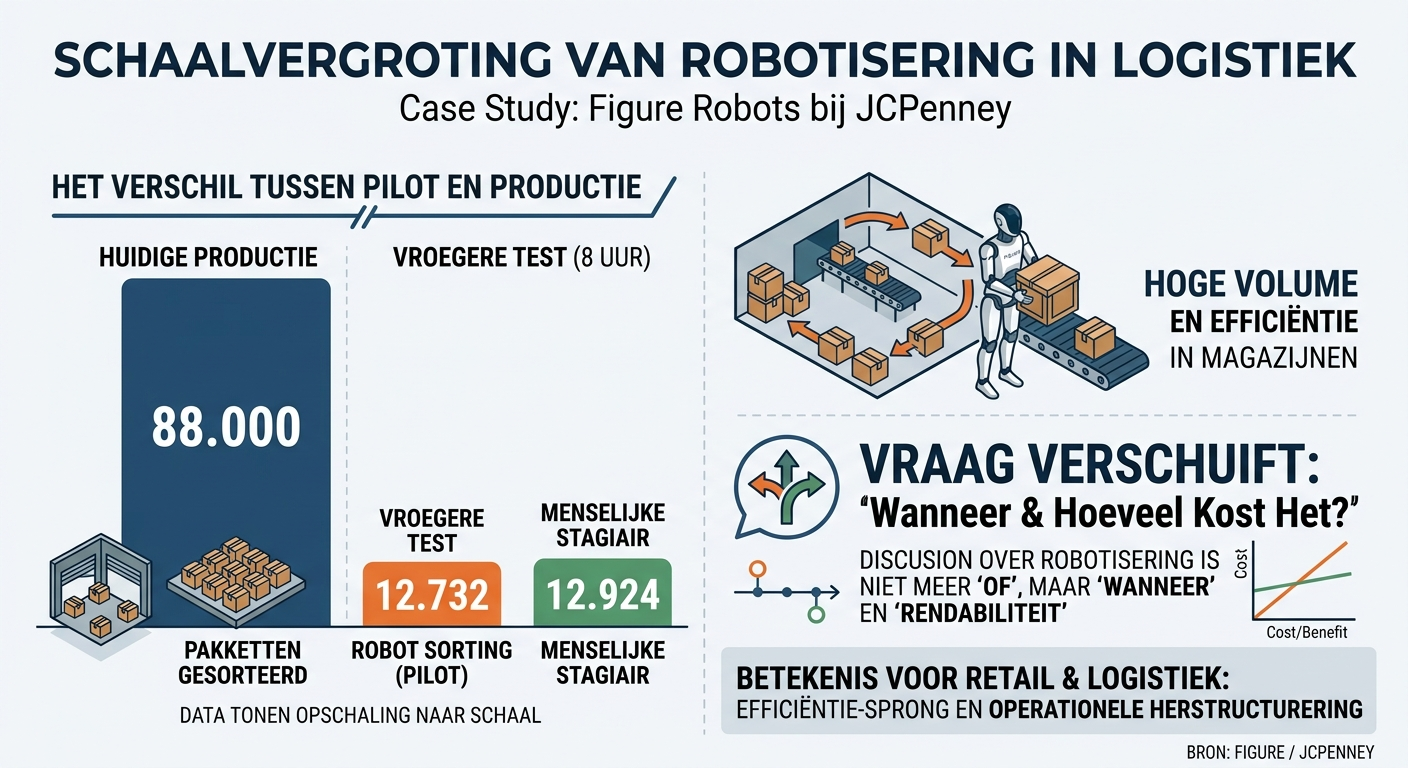
|
Bearly AI lanceert OpenADE met GPT-5.5, Codex en Claude CodeBearly AI heeft OpenADE uitgebracht, een ontwikkelomgeving die GPT-5.5, Codex en Claude Code combineert in één interface. Waar de meeste coding-tools een agent los op je codebase loslaten, richt OpenADE zich op de gestructureerde integratie van meerdere modellen tegelijk. Voor teams die al experimenteren met AI-ondersteund ontwikkelen biedt dit een manier om modellen per taaktype in te zetten, in plaats van alles door één model te sturen. Zet OpenADE deze week in op een klein project of feature-branch en vergelijk de output met je huidige workflow.
|