Verzonden op 09-04-2026 07:15

Anthropic's Claude Mythos spoort zero-day kwetsbaarheden opProject Glasswing is Anthropic's initiatief waarbij het nieuwe model Claude Mythos Preview wordt ingezet om kwetsbaarheden in kritieke software te ontdekken — nog voordat het model publiek beschikbaar is. Dat het model überhaupt wordt achtergehouden is opvallend: Anthropic stelt dat Claude Mythos duizenden cybersecurity-kwetsbaarheden heeft gevonden in browsers en besturingssystemen, en geeft softwareleveranciers via Glasswing vroegtijdig toegang zodat ze hun systemen kunnen versterken. Voor organisaties die afhankelijk zijn van veelgebruikte software is dit relevant: door kwetsbaarheden vóór brede AI-adoptie te dichten, verkleint Anthropic het aanvalsoppervlak dat modellen als dit zelf zouden kunnen creëren. Het is defensieve inzet van AI op infrastructuurniveau. Kanttekening: het model is nog niet publiek beschikbaar en Anthropic omschrijft de veiligheidszorgen zelf — onafhankelijke verificatie ontbreekt vooralsnog. Is dit voorzichtigheid of ook een stukje marketing? Waarschijnlijk allebei. Actietip: check of jouw softwareleveranciers deelnemen aan Glasswing of vergelijkbare vulnerability-disclosure-programma's. Dat geeft inzicht in hoe serieus zij AI-gerelateerde securityrisico's nemen. |
Claude Code kan nu automatisch pull requests repareren via CLIAnthropic heeft Claude Code uitgebreid met een PR autofix-functie die rechtstreeks vanuit de command line werkt — zonder dat je de IDE hoeft te openen. Voor ontwikkelteams betekent dit dat foutmeldingen en review-opmerkingen op pull requests automatisch kunnen worden opgelost als onderdeel van een CI/CD-workflow. Dat verkort de feedbackloop bij code-reviews aanzienlijk. De update sluit aan op een bredere trend waarbij AI-coding-assistenten niet langer alleen suggesties doen, maar ook zelfstandig correcties doorvoeren in de bestaande werkstroom. Vergelijk het met een junior developer die 's nachts de reviewcomments verwerkt. Kanttekening: automatisch doorvoeren van fixes vergroot ook het risico op stille fouten — zeker als de autofix geen volledige context heeft van de codebase. Handmatige review blijft voorlopig noodzakelijk.
|
Z.ai brengt open-source GLM-5.1 uit voor lange coding-takenZ.ai heeft GLM-5.1 als open-source model uitgebracht, specifiek ontworpen voor zogenoemde long-horizon agentic coding-taken — dat wil zeggen complexe programmeeropdrachten waarbij een agent meerdere stappen achter elkaar zelfstandig uitvoert. Voor teams die intern AI-coding-agents willen bouwen of draaien zonder afhankelijk te zijn van externe API's, biedt een open-source model als GLM-5.1 een serieus alternatief naast proprietary opties als Claude Code of GitHub Copilot. Het feit dat het model open-source is, maakt het ook interessant voor organisaties met strikte data-sovereiniteits- of privacyvereisten: de code blijft op eigen infrastructuur. Een concreet vergelijkend benchmarkoverzicht met andere modellen voor coding-taken was op het moment van schrijven nog niet publiek beschikbaar — check de officiële repo voor actuele cijfers.
|
Utah laat AI psychiatrische recepten verlengen — onder strikte voorwaardenUtah heeft een pilot van 12 maanden goedgekeurd waarbij het San Francisco-bedrijf Legion Health een AI-chatbot mag inzetten voor het verlengen van bestaande psychiatrische recepten bij stabiele, laag-risico patiënten. Het systeem is bewust beperkt: het kan geen nieuwe recepten uitschrijven, geen doseringen wijzigen en werkt niet met gecontroleerde middelen. Bij signalen van suïcidaliteit, manie of ernstige bijwerkingen wordt de patiënt automatisch doorverwezen naar een menselijke zorgverlener. Voor de zorgsector is dit een precedent: het is een van de eerste officieel goedgekeurde gevallen waarin AI een klinische handeling — het vernieuwen van medicatie — zelfstandig uitvoert, zij het zeer afgebakend. De vraag is niet óf AI in de zorg terechtkomt, maar hoe snel vergelijkbare kaders elders worden geaccepteerd. Kanttekening: het gaat om een pilot in één staat, met één aanbieder, onder strakke protocollen. Generaliseer de conclusies dus nog niet naar bredere AI-inzet in de gezondheidszorg. 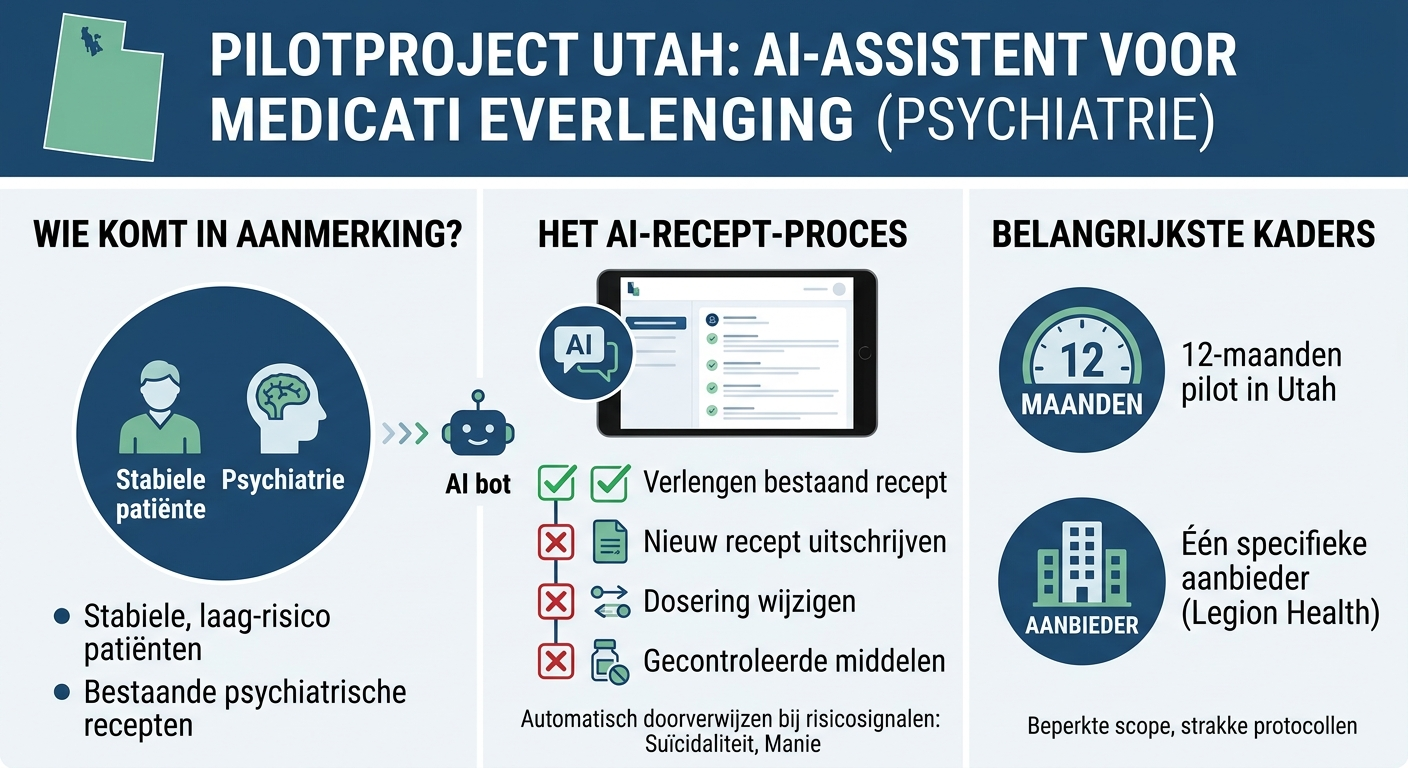
|
Google AI Overviews geeft in 10% van de gevallen onjuiste informatieEen nieuwe analyse toont aan dat Google AI Overviews — de AI-gegenereerde antwoorden bovenaan zoekresultaten — in circa 10% van de gevallen feitelijk onjuiste informatie bevat. Dat is relevant voor iedereen die medewerkers of klanten op deze antwoorden laat vertrouwen zonder verificatie. Zeker in sectoren als finance, recht of zorg kan een foutmarge van 10% aanzienlijk zijn. Het onderstreept een breder patroon: AI-zoekoplossingen zijn handig als startpunt, maar nog geen betrouwbare eindbestemming. Dit geldt overigens ook voor vergelijkbare functies bij concurrenten zoals Perplexity of Bing Copilot — onafhankelijke benchmarks voor die platforms ontbreken hier. Actietip: stel binnen je organisatie een korte richtlijn op voor het gebruik van AI-zoekresultaten: wanneer is een tweede bron verplicht, en voor welke beslissingen is AI-output onvoldoende als enige input?
|