Verzonden op 07-02-2026 10:08

Cursor toont proof-of-concept: duizenden agents onderhouden grote codebases autonoomCursor, de AI-IDE, demonstreert dat duizenden parallelle agents een enterprise-codebase kunnen onderhouden en doorontwikkelen zonder menselijke coordinatie. Elk agent pakt een specifieke taak (bugfix, refactor, feature) en synchroniseert via een gedeelde context-laag. Dit verschuift de discussie van 'kan AI coderen?' naar 'kan AI een heel engineeringteam vervangen?' De proof-of-concept laat zien dat schaal mogelijk is, maar roept meteen vragen op over governance: wie controleert wat er precies wordt aangepast als agents autonoom commits pushen? Business-perspectief: als dit mainstream wordt, dalen de onderhoudskosten van legacy-code drastisch. Technische schuld wordt sneller afbetaald. Maar introductie vereist stevige CI/CD-pipelines, geautomatiseerde tests en heldere rollback-procedures. Anders creëer je chaos in plaats van efficiëntie.
|
Anthropic en OpenAI lanceren binnen 20 minuten twee topmodellen voor codering en complexe workflowsOp 5 februari 2026 zette Anthropic Claude Opus 4.6 live, een model met 1 miljoen token context-window en 'agent teams' die autonoom samenwerken aan één taak. Geen 20 minuten later counterde OpenAI met GPT-5.3 Codex, uitgebreid tot een volwaardige computer-use agent die binnen de IDE blijft draaien. Waarom nu? Beide labs leveren een antwoord op hetzelfde probleem: AI-agents falen als codebases groot worden en taken langer duren. Opus 4.6 pakt dat aan met diepere planning en langetermijngeheugen; Codex door directe systeembesturing. Voor jouw organisatie betekent dit: minder handmatige tussenkomst bij codegeneratie en analyse van grote legacy-systemen. Teams kunnen complexere workflows automatiseren, van financiële rapportage tot juridische due diligence. Maar let op: de 1M-token context maakt deze modellen duurder in gebruik dan hun voorgangers, en 'agent teams' staan nog in research preview—verwacht dus kinderziektes. Concreet: test Opus 4.6 deze week op een interne codebase van > 100k regels en meet hoeveel minder handmatige context-injections je nodig hebt ten opzichte van Claude 3.5 Sonnet. |
Perplexity introduceert Model Council: één query, drie AI-modellen tegelijkPerplexity lanceert Model Council, een functie die één vraag parallel door drie verschillende AI-modellen jaagt en de antwoorden naast elkaar toont. Je bespaart tijd doordat je niet meer handmatig hoeft te switchen tussen ChatGPT, Claude en Gemini. Dit lost een reëel probleem op: elke AI heeft sterke en zwakke kanten (Claude excelleert in tekstanalyse, GPT in creatieve output, Gemini in multimodale zoekopdrachten). Model Council laat je in één oogopslag zien welk model het beste antwoord geeft voor jouw specifieke vraag. Business-impact: snellere validatie van AI-output en minder vendor lock-in. Je ontdekt welk model consistent het beste presteert voor jouw use case, wat aankoopbeslissingen gemakkelijker maakt. Wel een kanttekening: drie parallelle API-calls verdrievoudigen je kosten per query.
|
xAI lanceert Collaborative Notes voor co-authoring met AIxAI introduceert Collaborative Notes, een tool waarmee je context en kennisbases samen met AI kunt opbouwen en onderhouden. Denk aan gedeelde notitiedocumenten die de AI real-time aanvult met relevante data, bronnen en verbanden. Timing is interessant: terwijl Anthropic met Cowork inzet op kant-en-klare plugins voor niet-technische teams, gaat xAI voor flexibelere, open co-creatie. Het beantwoordt de vraag: hoe hou je institutionele kennis bij als AI steeds meer content genereert? Voor organisaties betekent dit: minder silo's tussen menselijke en AI-gegenereerde documentatie. Compliance- en onboarding-documenten blijven actueel zonder handmatige updates. Let wel: wie is eigenaar van co-authored content, en hoe voorkom je dat verouderde AI-input blijft hangen?
|
Meta publiceert nieuwe methode om kleine agents beter te laten presteren op complexe takenMeta researchers presenteren een techniek die kleinere, goedkopere AI-agents (denk GPT-3.5-niveau) even capabel maakt als grotere modellen voor specifieke, complexe workflows. De methode combineert taakdecompositie met gerichte fine-tuning op domeindata. Waarom relevant? Grote modellen als GPT-5 en Opus 4.6 zijn krachtig maar duur. Als je 80% van de kwaliteit haalt voor 10% van de kosten, verschuift de business case van AI-agents drastisch—vooral voor use cases met hoge volumes. Praktijk: organisaties die nu GPT-4 gebruiken voor klantenservice of dataverrijking kunnen overstappen op kleinere, zelf-gehoste modellen en zo marges verbeteren. Kanttekening: fine-tuning vraagt initiële investering in data-labeling en infrastructuur. Bereken of die opbrengst terugverdient voordat je begint.
|
Anthropic waarschuwt: infrastructuur verstoort benchmarks voor agentic codingAnthropic publiceert onderzoek waaruit blijkt dat infrastructuurkeuzes (CPU-snelheid, netwerklatency, OS-versie) de prestaties van AI-agents op coding-benchmarks met 15-30% kunnen beïnvloeden. Wat op papier het 'beste' model lijkt, presteert in jouw omgeving mogelijk veel slechter. Dit ondermijnt de vergelijkbaarheid van leaderboards. Als vendor A test op high-end hardware en vendor B op standaard cloud-instances, zijn de scores niet eerlijk te vergelijken. Het verklaart ook waarom interne pilots soms teleurstellen: de productieomgeving matcht niet de testopstelling. Actie voor je organisatie: benchmark nieuwe AI-modellen altijd in je eigen infra voordat je committeert. Gebruik representatieve datasets en productiehardware. Een 'top-3 model' kan in jouw stack een underperformer blijken. 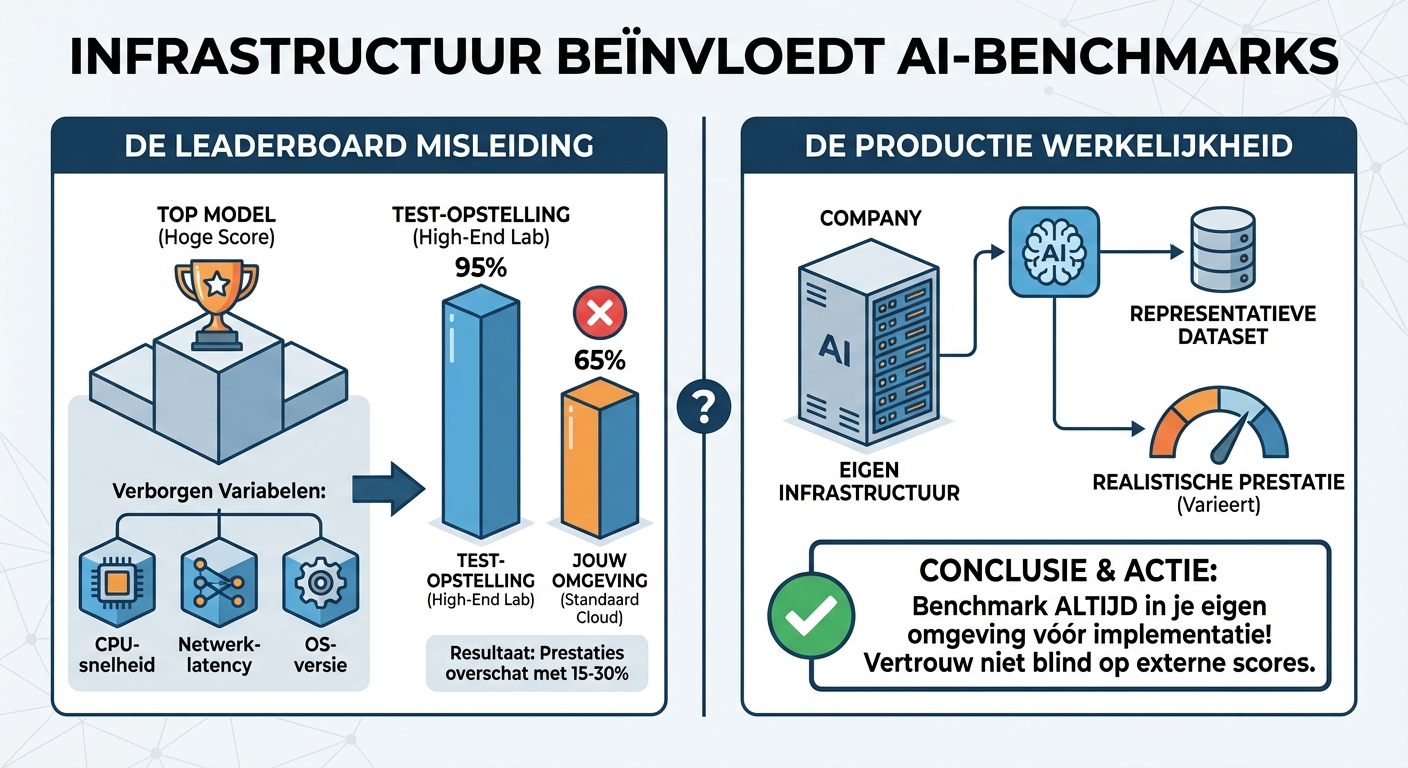
|