Verzonden op 17-10-2025 07:18
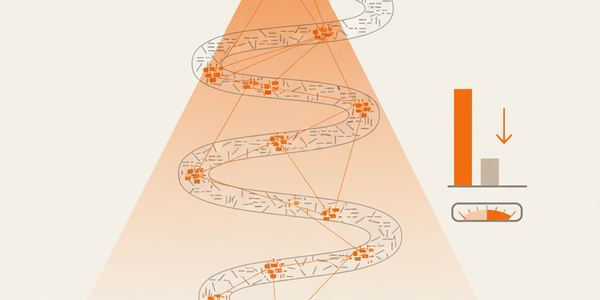
DeepSeek verlaagt inferentiekosten met dynamische sparse attentionDeepSeek heeft de weights vrijgegeven voor DeepSeek-V3.2-Exp, een model dat inferentiekosten voor lange contexten significant verlaagt door selectief alleen de meest relevante tokens te verwerken. Voor applicaties die grote documenten of lange conversaties moeten verwerken, is dit een belangrijke ontwikkeling. Het kan de kosten voor het verwerken van een context van 128.000 tokens verlagen van $2.30 naar $0.30 per miljoen tokens, wat taken als het analyseren van juridische dossiers veel betaalbaarder maakt. De winst in efficiëntie komt wel met een lichte, maar meetbare daling in prestaties op bepaalde benchmarks in vergelijking met zijn voorganger. Het is een afweging tussen kosten en absolute topkwaliteit. Actie-tip: Draai een batchverwerking van een van je langste documenten door zowel de API van DeepSeek-V3.2 als je huidige model. Vergelijk niet alleen de kosten, maar ook de kwaliteit van de samenvatting om de trade-off te beoordelen.
|
Anthropic lanceert Claude Haiku 4.5: snel en significant goedkoperAnthropic heeft Claude Haiku 4.5 gelanceerd, een kleiner model dat de codeerprestaties van het vijf maanden oude Sonnet 4 evenaart, maar voor een derde van de prijs. Dit maakt geavanceerde AI-toepassingen economisch haalbaarder voor een bredere groep. Denk aan het orkestreren van meerdere, parallel werkende AI-agenten voor complexe taken, waarbij Haiku de snelle 'uitvoerders' zijn en een groter model als coördinator fungeert. De prijs per miljoen input tokens is slechts $1. Hoewel de prestaties op benchmarks indrukwekkend zijn voor de omvang, zal het voor de meest complexe redeneertaken nog steeds onderdoen voor de absolute topmodellen zoals Opus. Actie-tip: Test Haiku 4.5 voor taken die snelheid en volume vereisen, zoals het categoriseren van klantfeedback of het genereren van meta-descriptions. Vergelijk de outputkwaliteit en de kosten direct met je huidige, duurdere model om te zien waar je kunt besparen zonder kwaliteitsverlies. |
Google's Veo 3.1 geeft videomakers meer creatieve controleGoogle heeft Veo 3.1 gelanceerd, een upgrade van zijn AI-videomodel die zich richt op praktische, creatieve controle in plaats van pure generatie. Voor content- en marketingteams wordt het nu mogelijk om video's te produceren met consistente karakters (via referentie-afbeeldingen), scènes naadloos te verlengen tot meer dan een minuut, en objecten te bewerken na generatie. Dit verschuift de tool van een 'leuke gadget' naar een serieus productiemiddel. Ondanks de functionele upgrades, lijkt de visuele realisme-lat die concurrent Sora 2 recentelijk heeft gelegd nog niet te worden geëvenaard. De focus ligt hier duidelijk op bruikbaarheid en workflow-integratie. |
OpenAI sluit miljardendeal met AMD voor schaalvergrotingOpenAI gaat voor tientallen miljarden dollars aan AMD Instinct GPU's afnemen en krijgt de optie om, onder voorwaarden, tot 10% van de aandelen van de chipmaker te verwerven. Deze deal is een strategische zet van OpenAI om zijn afhankelijkheid van Nvidia te verminderen en de enorme rekenkracht voor toekomstige datacenters veilig te stellen. Voor de markt betekent dit dat AMD nu een serieuze, gevalideerde concurrent voor Nvidia wordt in het high-end AI-segment. De deal dekt genoeg GPU's voor 6 gigawatt aan stroom. De voltooiing is echter complex en afhankelijk van het behalen van specifieke, grotendeels onbekende mijlpalen door beide bedrijven. Het is een grote gok op de toekomst, waarbij beide partijen hun lot aan elkaar verbinden.
|
Mira Murati's startup vereenvoudigt fine-tuning met Tinker APIThinking Machines Lab, de startup van voormalig OpenAI CTO Mira Murati, heeft zijn eerste product gelanceerd: Tinker, een API die het fine-tunen van taalmodellen over meerdere GPU's automatiseert. Dit verlaagt de technische drempel voor R&D-teams en startups aanzienlijk. In plaats van je bezig te houden met resource-allocatie, kun je je richten op het fine-tuning script zelf. Door LoRA-adapters te gebruiken, kunnen de compute-kosten bovendien worden gedeeld over meerdere runs, wat experimenteren goedkoper maakt. De tool is momenteel nog in een 'waitlist'-fase en biedt een beperkte selectie van modellen (Qwen3 en Llama 3). De daadwerkelijke kosten en prestaties op schaal moeten zich in de praktijk nog bewijzen. |
Google's AI ontdekt nieuwe aanpak om immuunsysteem tegen kanker te helpenOnderzoekers van Google en Yale University hebben een op Gemma-gebaseerd model gebruikt om een voorheen onbekend mechanisme te ontdekken dat tumoren zichtbaarder maakt voor het immuunsysteem. Dit is een tastbaar bewijs dat AI kan bijdragen aan fundamentele wetenschappelijke ontdekkingen. Het model identificeerde een bestaand medicijn, silmitasertib, voor een compleet nieuwe toepassing, die vervolgens in labtesten werd bevestigd. De zichtbaarheid van tumorcellen nam met circa 50% toe. Dit is een vroege maar veelbelovende ontdekking. De weg van een bevestigde aanname in het lab naar een daadwerkelijke, goedgekeurde behandeling voor patiënten is vanzelfsprekend nog lang en complex. |
Gmail automatiseert plannen van afspraken met 'Help me schedule'Google rolt een nieuwe Gemini-functie uit in Gmail die het plannen van een afspraak automatiseert. Dit pakt een alledaagse frictie aan: het heen-en-weer mailen om een geschikt moment te vinden. De tool analyseert de e-mailconversatie en je Google Calendar, stelt direct in de e-mailreply geschikte tijden voor, en creëert automatisch een agenda-uitnodiging zodra de ander een tijd kiest. Het is een subtiele maar krachtige integratie van AI in een kernproces van de werkdag. Momenteel werkt de functie alleen voor één-op-één-afspraken en het is een voorbeeld van hoe je dieper in een specifiek ecosysteem (in dit geval Google Workspace) wordt getrokken. |